We built AXIS to answer a question we couldn’t stop asking.
How well does Netlify actually work for AI agents?
Agent Experience (AX) is the holistic experience AI agents have as users of a product or platform. How well they can discover what your service does, call it reliably, and recover when something goes wrong.
Agent Experience has had a good year. When Mathias introduced the concept in 2025, it was a bet that how AI agents interact with software would matter as much as how humans do. a16z has written about it. A Queen’s University study found that 97% of MCP tool descriptions had quality issues. Not because the protocol failed, but because nobody was designing for the agent on the other end.
The belief has aged well. But belief isn’t a standard.
So we built AXIS to measure it
AXIS is open source tooling and a scoring framework to measure how well services work for AI agents. Think Lighthouse, but for Agent Experience.
You give it a scenario – a JSON file with a prompt and a rubric – point it at an agent, and it runs the agent against your endpoint.
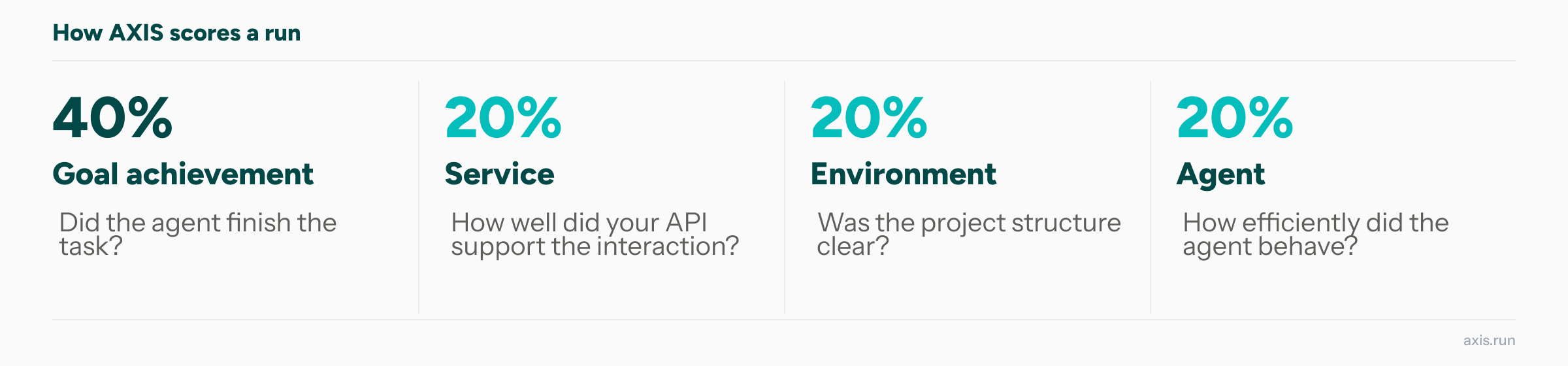
AXIS comes with native support for 22 agents including claude-code, codex, gemini, cline, goose, cursor-agent, and copilot. Each run captures every tool call, response, recovery attempt, and produces a score across four dimensions.
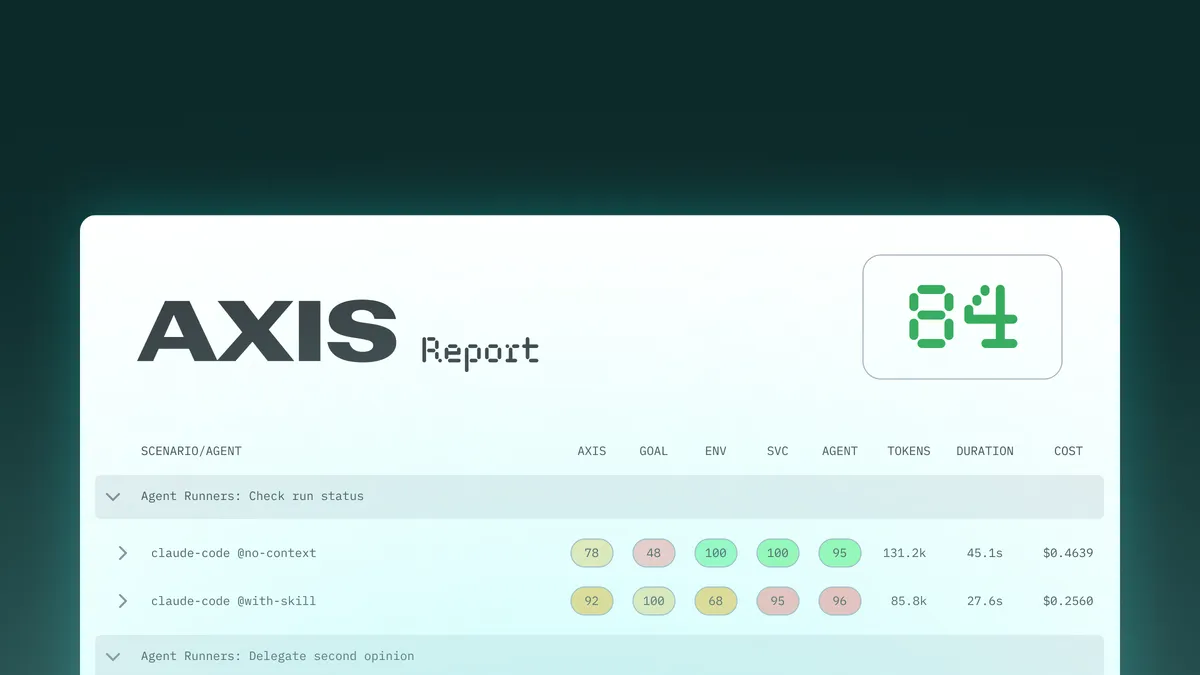
The result is a 0–100 score with a fully inspectable HTML report – see an example AXIS report. Ultimately, it’s a number you can act on and track over time.
We ran it on ourselves first
Before we announced AXIS, we ran it on Netlify. We want to improve our own AX, of course, but the bigger goal is helping others improve theirs.
Here’s what running AXIS on Agent Runners showed us:
| Scenario | Agent | Condition | Score | Time | Tokens |
|---|---|---|---|---|---|
| check-task-status | codex | no-context | 68 | 22.3s | 78,260 |
| codex | with-skill | 98 | 25.4s | 87,563 | |
| claude-code | no-context | 78 | 45.1s | 131,163 | |
| claude-code | with-skill | 92 | 27.6s | 85,773 | |
| delegate-local-wip | codex | no-context | 63 | 66.1s | 226,082 |
| codex | with-skill | 98 | 28.9s | 119,280 | |
| second-opinion | claude-code | no-context | 69 | 139.9s | 450,558 |
| claude-code | with-skill | 95 | 109.0s | 240,509 |
Three scenarios, two agents — Claude Code and Codex — each run cold (no context) and with skill.
Across all three, skills lifted scores by an average of 26 points and reduced both time and cost on every run. That’s what happens when an agent has the context it needs rather than guessing. AXIS is what made the gap visible.
Overall AXIS result for Agent Runners: 84/100. The team now has a baseline we can build upon and make sure we’re serving agents well.
How we’re making this stick
A finding is a data point. A practice is what makes progress.
Netlify’s agent context – skills, MCP server context, CLI context – lives in four or five hand-maintained places today. It drifts from the documentation it’s supposed to reflect. The experience of using Netlify directly and using Netlify through an agent are inconsistent in ways we can’t always see. AXIS helped us name and quantify that.
Now we’re building toward fixing it structurally. This week we’re landing AXIS scenario coverage across the Agent Runners orchestrator repo.
Next, we’re trying to fix the silent drift. We’re creating a context pipeline that automates the generation and verification of agent context directly inside the repos that already hold the human-facing documentation. Moving to a model where:
- Developers keep updating docs.
- The pipeline derives, tests, and publishes the corresponding agent context automatically.
- New docs can’t ship without a deliberate decision about their agent context.
AXIS is the verification layer that makes this possible. On every PR that touches source material, the pipeline runs the relevant scenarios, scores the result, and reports inline. A regression fails the build the same way broken tests do. On merge, verified context propagates to every downstream surface automatically.
We’re in the RFC stage. But the direction is clear. Agent Experience shouldn’t be something we audit once or periodically. Building it into our engineering practices is the only way.
Try it, or help build it
Auth0, a founding contributor to AXIS, put it well:
“Agent Experience is now a core part of how developers evaluate identity infrastructure. We built Auth0’s Agent Experience Score to measure it rigorously across models and frameworks, and that work made clear the industry needs a common, shared benchmark to do the same. That’s why Auth0 is proud to be a founding contributor to AXIS.” — Bharath Natarajan, Group Product Manager at Auth0
Every service that interacts with AI agents has this challenge. Most just don’t know it yet. Run AXIS, see where the friction is, and improve it.
Working on an API, CLI, or MCP? Test out AXIS and let us know what you think. Initializing it includes a skill to generate your own scenarios and give you results in minutes.
npm install @netlify/axisaxis initaxis runDocs and quickstart at axis.run. If you want to contribute your ideas are welcome – check out the roadmap and the repo at github.com/netlify/axis for some inspiration.





