Do you love waiting for web content to load? Of course not, and neither do your customers. Netlify is on your side, helping you deliver content to browsers before your visitors can blink.
Between the speed benefits you already know from using the JAMstack and some intelligent content caching, your visitors get a great experience. In this post I’ll explain some of the finer points of caching and how we do it at Netlify.
Let’s talk about caching possibilities in general. There are a lot of places caching improves your computing experience — using RAM as a cache for much slower disk access; using CPU on-die cache to speed things up versus much slower RAM access. But on the web, there are 3 major places that caching can help you:
- CDN
- proxy
- browser
In this post I’ll mostly be talking about the browser and the CDN, but for the curious, caching proxies like Squid tend to act as kind of a shared browser. That is to say, they cache things from our CDN much like a browser would, with the goal of preventing (where possible) round trips to our CDN node by all browsers that use it — which may mean that someone else benefits from the cached item that you initially looked at. Our directives to the browser about how long and what to cache are also respected by properly configured caching proxies.
This article from google does a better job of explaining the whole process in more detail than I will, so go read that if you’re really curious about all the details, but I’ll walk through how we implement them at a high level at Netlify. In effect, a web server tells a browser a few things about every single file it downloads:
- Can this be cached, and if so by whom? (HTTP header: cache-control — private vs public)
- How long can it be cached for? (HTTP header: cache-control — max-age)
- How can I tell if it’s been changed? (HTTP header: etag in combination with above)
So, what’s our secret sauce? From a browser point of view, things work just as described above — we send caching headers that your browser (and/or proxy) obey to prevent the re-download of unchanged content. However, supporting atomic deploys and rollbacks causes us to use the system a bit differently than other CDN’s, so I’ll explain.
You may have heard that cache invalidation is one of the hardest problems in computer science, and we agree. Nonetheless, we think we have a solid implementation that will benefit you and your visitors. When we send those Cache-control headers, ours look a little different than you’d expect. Here’s a view of some headers for a typical file we served, from the developer tools in Chrome:
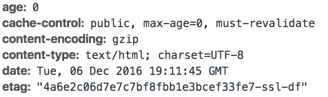
With these headers, we are saying specifically:
“max-age=0, must-revalidate, public” = “please cache this content, and then do not trust your cache”. This seems a bit counterintuitive, but there’s a good reason. This favors you as a content creator — you can change any of your content in an instant. Let a broken page out in a deploy? Roll back instantly. Want to make sure that your new marketing site all goes out — text, code, and assets — at the same instant so your visitors don’t experience the dreaded new/old mixture that old, file-at-a-time deploy methods left you with? We’re ready!
“etag” = a version hash, which we send with all content, that the browser provides BACK to our servers when it tries to re-fetch one of these resources (as you saw above — we’ll always set assets to require re-fetching). A browser tries a conditional get in this situation, providing the etag with the initial request to let our server confirm that this version is still current if the etag we would serve with the new content matches, our server returns an HTTP 304 which allows the browser to use its cached content instead of the client having to re-download the content.
From a browser point of view, this sounds terrible — the browser has to check in with our servers for every file it wants to load? Even if it is literally just a page reload in an identical browser session 1 second after the last load? Yes! But it isn’t so terrible due to 2 pieces of magic:
- Our CDN
- Use of HTTP/2
The CDN makes the check-in from the browser fast — it talks with the node closest to it and that node is ready with an instant answer as to whether the content is usable as-is (Etag matches, no deploys or rollbacks have happened). Using HTTP/2, browsers multiplexes these connections so they can all happen within a single connection and you don’t have to do things like negotiate the HTTPS handshake over and over again.
Note: you can override these caching settings with our custom headers feature, and you can experience the benefits of our asset post-processing into long-term-cacheable-without-revalidation if you enable Asset Optimization for your site — but we’ll need another blog post to talk about that how and why.






