Distributed system design is hard. There are many decisions that you need to make in the architecture early that have long reaching impacts. One of these decisions is how systems will communicate.
-
Will components expose RESTful APIs?
-
Will they interact with a messaging system (e.g. RabbitMQ, NATS, Kafka)? GRPC?
-
How will they share responses?
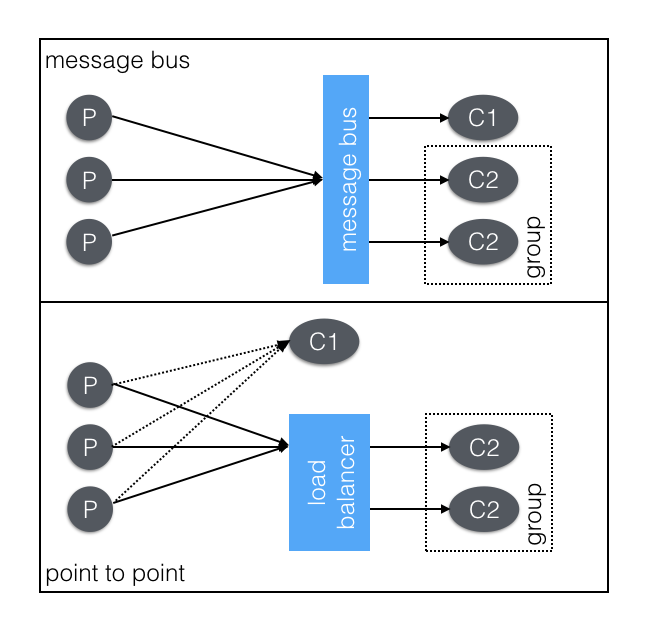
I think that communication roughly falls into two schools: point to point and message bus.
In an architecture driven by a message bus it allows more ubiquitous access to data. The consumers are allowed to determine how they will consume the data. It is not something decided by the sender. The power created by decoupling the producer and consumer, far outweighs any operational overhead introduced. Point to point is easier in some ways, but it silos the data off from the rest of the system. This can be a perk, security and isolation for instance, but building these walled gardens of data will hurt innovation, development pace, and monitoring in the long run.
Often systems will use a hybrid of the two communication styles. For instance, we have a service that will take commands from a message bus, but are provided a callback URL where they can funnel the responses. It could have easily been that we just send messages back on the bus. We chose the hybrid approach because it fit the existing architecture better. We could have also stood up a proxy/load balancer that would have distributed the messages but looked like a single instance.
Point-to-Point
In point to point, you’ll communicate between services directly. For instance, you’ll POST metrics directly to an endpoint, or funnel logs, or request an action. For scalability, you’ll often need to consider having multiple instances supporting that endpoint. To do this you’ll have some kind of load balancer or proxy. Setting up an maintaining proxies can be cumbersome, but they also provide a huge amount of power. Usually, you also have to address service discovery earlier in the system design.
Using load balancers to distribute load across multiple instances, is very helpful, arguably essential when designing the system. Once in place it allows you to easily load multiple services into a box and provide a consistent port signature. However, the most powerful feature is the ability to fail an instance out of the load balancer. This allows the running production instance to stay running for troubleshooting while not compromising the integrity of the whole system. This flexibility is invaluable when you have a lot of services collaborating on a single logical request.
The biggest drawback of a point-to-point communication structure is that the data is silo’d in the ecosystem from which it originates. The creator of the information determines how the data is used, by sending that data to a single point. This means that new crosscutting capabilities have to go fundamentally highjack that communication channel. They have to man-in-the-middle the receiver to get access to that data. Simple things like ‘how many requests is that service getting’ have to be built in and can’t be added afterwards.
Message bus
Using a message bus will allow for the same communications, but it’s a little more simple. Single request/reply, worker pool, and broadcast models are supported out of the box. Service discovery is a matter of just sending messages to the right topics. There is an operational cost of maintaining the message bus, and possibly having a piece of infrastructure that impacts all services. But, all the production grade buses support clustering, but still things can go wrong and it can lock the whole system up (looking at you RabbitMQ).
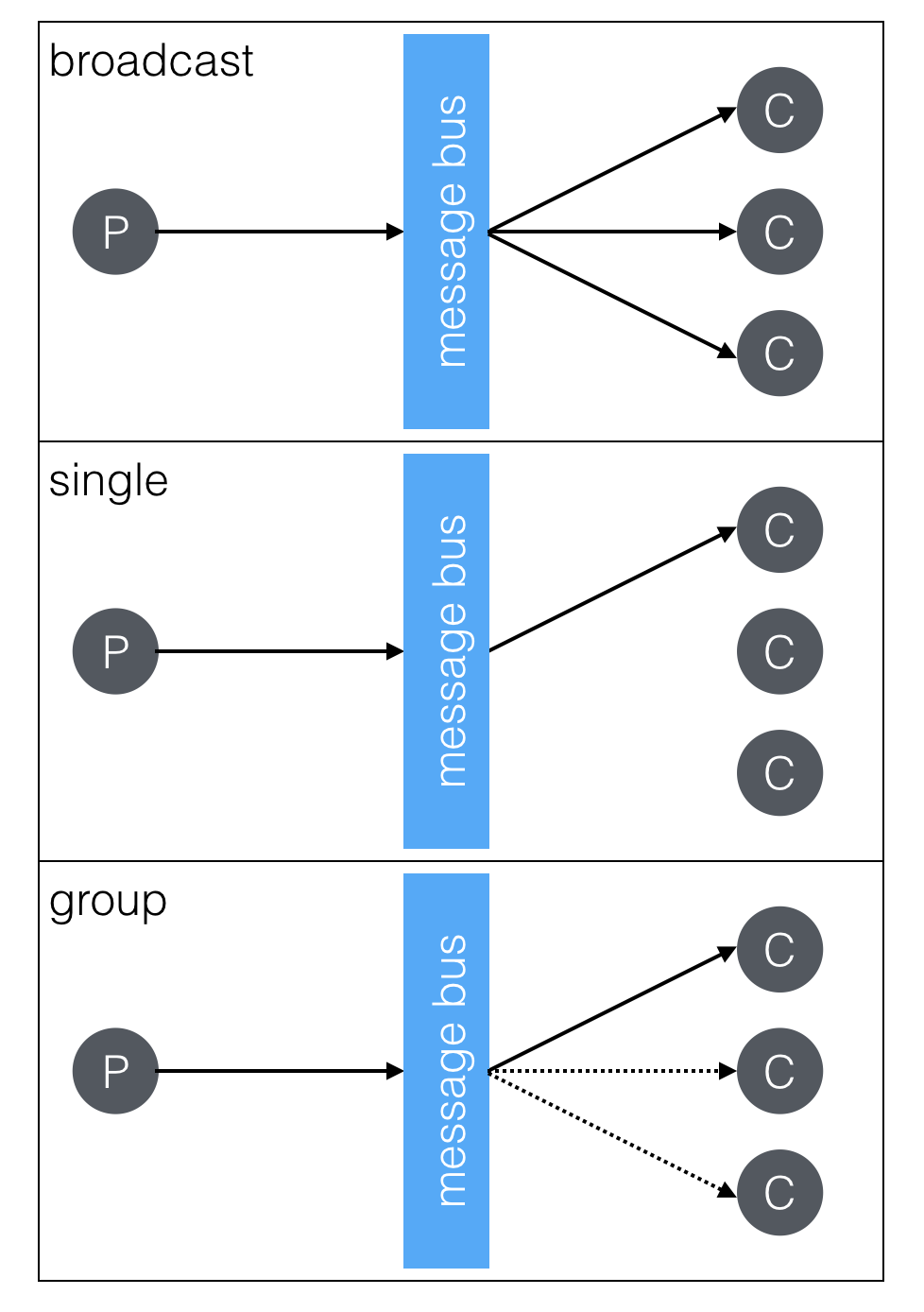
The primary benefit of a message bus architecture is that data is freely available. Services just provide data and don’t mandate how it is used. You still have the necessary coordination in developing a system; part a generates messages like this and part b will do that. But now you can have any new service start non-destructively consuming those messages. This free flow of data allows for rapid prototyping, simple services crosscutting, intuitive monitoring and easier development.
As an example you can look at how Netlify collect metrics from across the system. Each of our services has a message bus connection logging, command & control, and metrics. We knew that each of the services would need to be pushing out metrics (read: counting things), but we weren’t sure where we would be storing them. Because the data was just on the bus I could easily create a few different services that took the data and pushed it to different storage engines. I was able to quickly side-by-side influxDB, redshift, dynamo and a 3rd party system with no modifications to the actual services. I built some quick command line utilities to tap into streams and run little experiments (e.g. validating counts, debugging, monitoring throughput).
All of these experiments are developed independently as I needed them. This flexibility let me ask a question and quickly answer it without potentially impacting the actual service. I could quickly look at real production data to answer any questions that came up. All of those perks is because the data wasn’t walled off, anyone with access to the message bus (which is secured) could look at the data without impacting other services.
Without a load balancer it is more difficult to leave an instance running but not communicating with the system directly. It requires specific code and for the end user to build this, not just configure the load balancer. There are also security concerns, once on the bus a consumer can start listening to data very easily. Enterprise messaging systems sometimes provide out of the box ACLs, but it is not in everyone. I would contend that this ease of access is far more valuable and worth the security considerations.
Communicating between components
There are a handful of ways to design communication systems in a distributed system. An architecture with a message bus as a core feature is very powerful. The decoupling between data creation and data consumption is invaluable in a growing system. New services can easily collaborate using the bus, and service agnostic tools (e.g. a message tailer) can interoperate easily. Point-to-point systems have some clear perks, but I think they’re outweighed by the capabilities created by a message bus.
Coordinating disparate systems is complex to say the least, designing how they communicate is vital to there success. But, which school is best for your system? As is always the case with engineering, the answer is “it depends”. Hopefully this helps you qualify which is the best for you.






