One of the most valuable skills one can possess as a developer is to learn how to scope down your work into manageable pull requests (PRs). Why the emphasis on something as seemingly trivial as size? There are many reasons, but here are some of the most pertinent:
- It’s easier on reviewers
- It’s easier to test
- It’s easier to iterate
We’ll dive into some of those whys, and then move on to the hows: the processes you can use to scope PRs down, as well as who on your team can assist.
Why Do We Scope Down?
Small PRs are easier on reviewers
If someone has to read through and make sense of your code in order to evaluate it, it’s much easier to get through if it’s smaller and more focused. Think about it from the reviewer’s standpoint: it’s their job to make sure whatever code they’re reading makes it through this process in the best state possible. The smaller the amount of code, the lower the cognitive load you impose on them to envision all the moving parts and any potential side effects.

The higher the number of changes, the more conversation you’ll have to have.
It also requires reviewers to do much more work as a communicator, which takes two skills: the actual code review, and the ability to communicate how/why the changes need to be made. As a reviewer, sometimes I’m handed huge chunks of code, some of which I would like to take, some of which I can’t. This means I now have to break these concepts apart, explain the differences between them, and talk through an iteration plan. This is ok, but a lot more mental overhead for everyone involved, particularly because it can potentially be damaging to the team if the communication goes poorly. Smaller PRs keep the conversation focused, and as such, reduce the need for any communication gymnastics.
Small PRs are easier to test
Large PRs mean there are more potential side effects and moving parts. It becomes more opaque to see what’s been altered. When there are less moving parts, it’s not just more clear what the testing strategy is, but also how much coverage the tests offer.
For instance, if I have an enormous PR and there are a few tests, I have to still spend a good amount of time matching the contents of the PR with the types of tests involved to see if the coverage is adequate.
Having fewer moving parts also makes it clear what else in the codebase is affected, the bigger the PR, the more potential surprises you might have. It’s easier to iterate if work needs to be adjusted, revisited, or not accepted, there’s much less investment, both personally and in terms of developer time. The chance that you went in the wrong direction for a long time without any course correction increases with the size of the PR.
Some of this investment is personal: you might be more attached to your work at that point and less willing to take in feedback. Some of this investment is a business concern: developer time is expensive. If you went heads down for a week and didn’t communicate, and some of the work can’t be used, that’s not helpful to the company’s bottom line and ability to ship products.
When you create smaller pieces of work, you can adjust and communicate more quickly, even as things outside the project change, if there are shifting priorities. Your teammates will also trust that they’ll see subsequent work from you soon. You might be amazed at how much more quickly they’re willing to review your work and get it in.
How do we break down a project?
There are a number of tools at our disposal for scoping work down. They may not all might be available to you, though, so let’s go over them.
Clear Expectation of Output
This one has less to do with tools and more to do with people. If your company has a Project Manager role (this is different from a Product Manager), they are typically very effective in helping break down tickets into more manageable units and estimating the size and time of the work. On some teams, this duty falls more to the Engineer Manager or Product Manager.
If you find that this person isn’t accustomed to this duty, or you’re the one in charge, here are some suggestions: it’s incredibly difficult to estimate engineering work — some things that you think will take 2 minutes turn into hours or days, or vice versa. So start with the end. What output do you expect to see from that ticket? Now, we can walk backwards. What parts of the codebase will be affected in this change? If you’re newer to the project, ask someone with more seniority on the team to help you track which areas will need to be updated. If possible, break those into disparate tasks. Even if they are dependent on one another, you can usually find a way to break it into step 1, step 2, and so forth. If you’re using the branching model outlined below and communicate to your reviewers clearly, they know to expect many pieces of work from you and not one giant finished product.
Branching
In a branching model, you communicate what you’re working on through the iteration of work on branches. Typically these branches are named semantically with the project in question: FeatureName or RefactorName, sometimes with versioning as well. The nice thing about using branches like this is that you can do frequent work in one place, and no one is expecting everything to be done in one go.
But branching does require coordination: people on your team should know that this work is correlated to a certain piece and not to merge it until the work is complete. If there is a ton of work that needs to be done on a specific branch, you likely need some end to end tests to validate that the merge won’t break anything.
Labels
I typically have my teams use branching with labels to scope down work, they’re very effective when used together. For instance, maybe you’re working on one part of a particular feature that’s part of a 1.0 roadmap. Your coworker is working on another piece. If you both use the same label but different branches, you can clearly see who is working on what and make sure the changes are tracked together. This means everyone can work incrementally because there’s insight into what work is done globally on a project as well as the small parts.
Feature Flags
It’s also possible to use feature flags to gate checks, and merge code in slowly that you can test in production. When I worked at Trulia/Zillow, we would use this model frequently with cookies that one could set in their browser, so that stakeholders could not just check against it, but we could also run split-testing and work out conflicts long before it ever hit primetime. We would roll things out to prod slowly, monitoring the work in partnership with other teams as we went. It allowed us to be very coordinated, which was especially important for big releases with a lot of moving parts.
We made good use of feature flags here at Netlify for our most recent release of faster deploys. Specifically, we use a Ruby gem called Flipper. We like testing in production, and our process allows us to roll out from day one in production and make good use of telemetry to monitor how well the changes are functioning.
Number of Concerns
The most effective PRs I see and ones I love as a reviewer, are small, focused, and scope the work down to the smallest number of concerns. Think through your work in terms of how many things are changing, and try to limit this number as much as you can. There’s a great post here about the Single Responsibility Principle, which outlines how every module or class should have responsibility over a single part of the functionality, and how this can be applied to pull requests as well.
It might seem at first that it’s critical that all changes be made at once, but you’ll find over time with the branching model, that this isn’t necessary. You can communicate to people within the PR that there’s more work to do as well.
Furthermore, each PR should, when possible, only have one goal so the next iteration can build on it. In other words, if you’re both refactoring old code, and introducing new tests, that’s much harder on a reviewer than if it is split. If you have two iterative PRs, it’s easier to ensure the functionality didn’t change prior to modifying the implementation.
Tracking what’s left
If you’re going to leave unfinished work, it’s helpful to keep track of what’s left. This is not just for you, but for any stakeholders like your teammates or PMs. A lot of teams will make use of project boards for this, which also helps you go over what’s going on in the project as a group

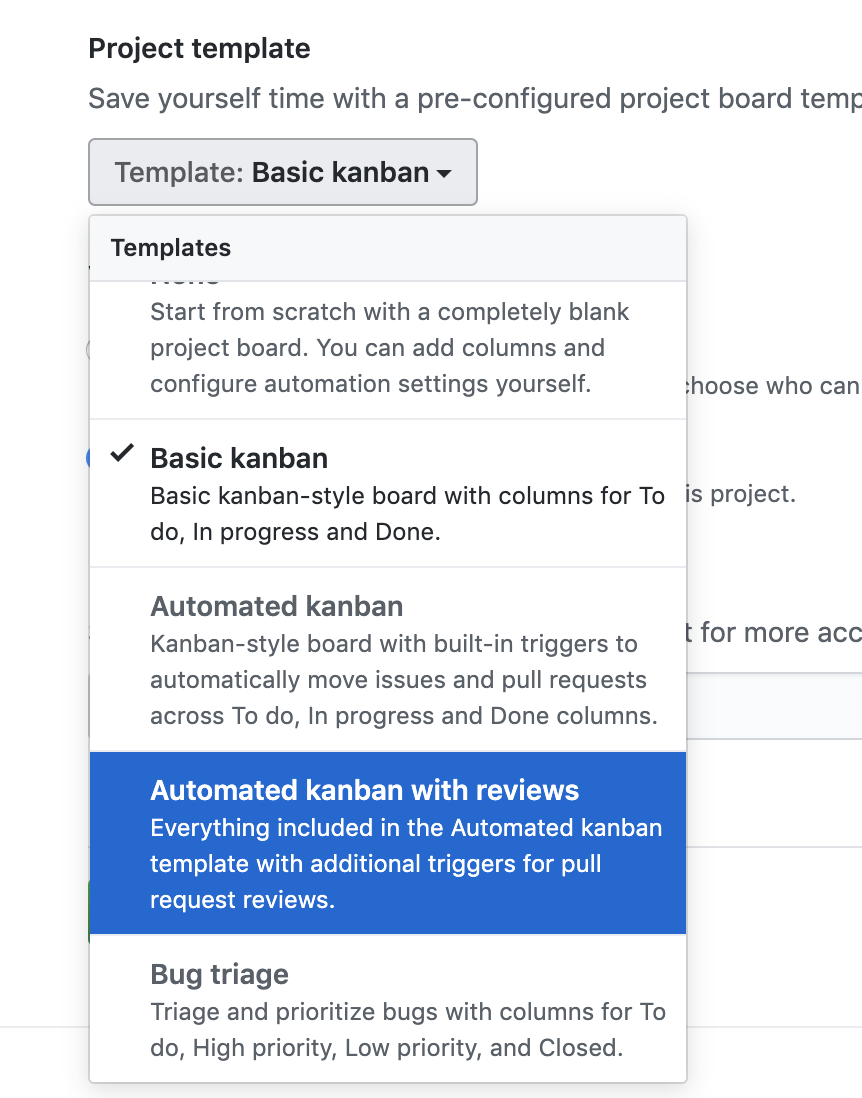
Example GitHub Board, you can add in issues as well as notes.
Some tools like GitHub and Jira will help you with some automation as well:
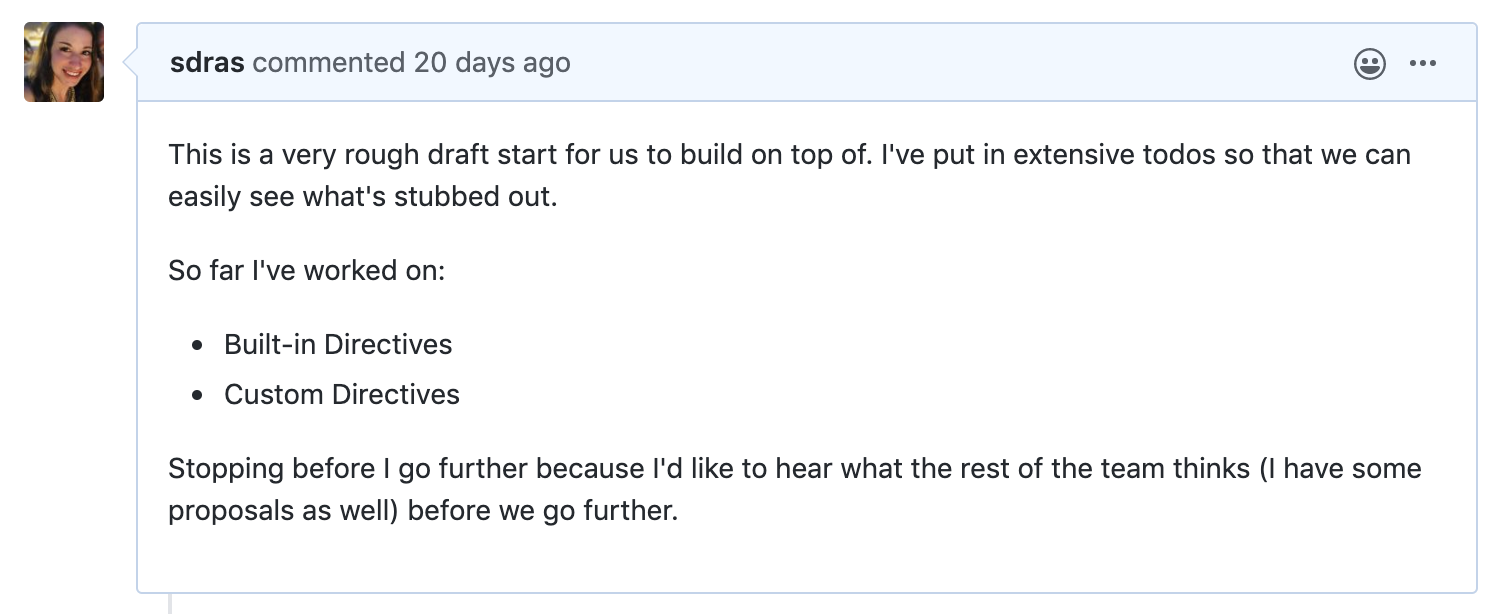
Even if you’re tracking things within these boards, it can be useful to your coworkers/reviewers to do a todo list or list of changes in the PR itself as well. This helps them immediately see the scope of the PR without having to check any other references, which can help with speed of execution:
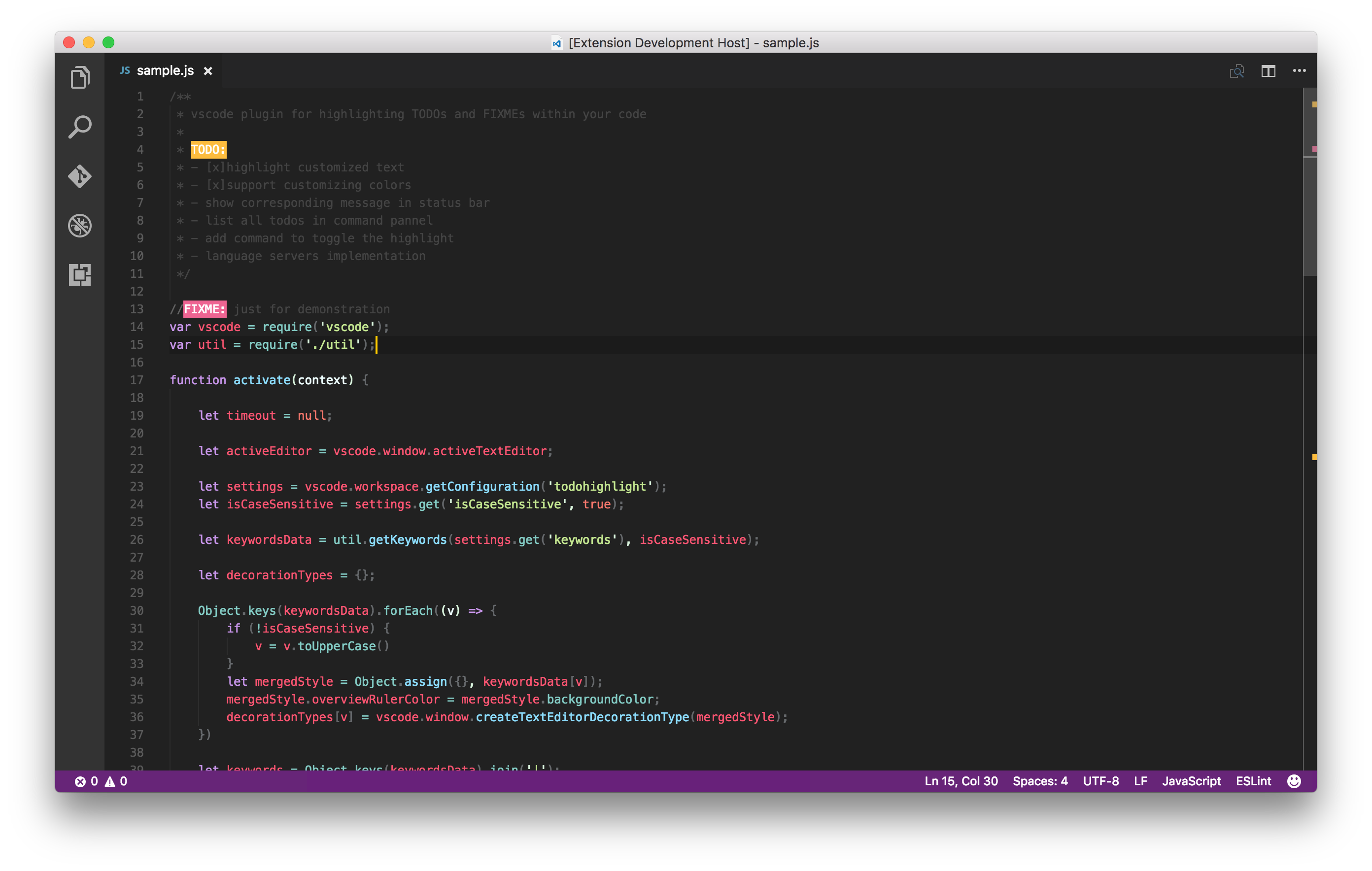
As mentioned above, you can also make use of To dos — I do this sometimes, and will track what’s left with this VS Code extension that goes through and highlights any to do comments for you. You can also override and customize it, should your team have a different convention.
These are just a few ways to track work at the developer level. Truly, there is a whole project management discipline that employs many different tools and techniques! Covering everything is out of the scope of the article, but hopefully these help while coding.
Working on a few pieces at once
This one is tricky, but a skill you might develop as you level up. As you get better at scoping down work, you’ll find that there are times that you’re waiting for review on these smaller pieces, so what do you do with that time? In fact, I think this is where some will assume that one large PR is more effective because they can spend the time working before submitting the PR. Unfortunately, this will often come back to haunt them when it gets locked up in review.
As you get better at breaking large projects down, you also start to learn how to cut work up into many pieces and have two concurrent pieces of work that are not reliant on each other. Perhaps in a personalization project, there are changes that need to be made within the navigation, as well as updates to the data coming into the sidebar. They may be similar pieces, but figuring out ahead of time how to break them apart does a few things: can cause fewer side effects as the nav and the sidebar are now not potentially going to break one another, and while you’re waiting for the nav review you can get cracking on the sidebar piece. This is a simplistic example but illustrates that you can plan for this situation ahead of the actual work to make the most use of your productive hours as possible.
Wrapping up
Hopefully this helps you and your team be more effective, work through problems quicker, and review code more effectively! Have more to add to the conversation? You can let me know on twitter, or in our Community.






