
What if you realized you could optimize the structure of an existing system by doing less work? We can probably all attest that it's one thing to notice an opportunity, and an entirely different beast to actually roll it out into production. This is the story of how the infrastructure team at Netlify took a 4 year old codebase and isolated an issue, tested a few different solutions (with some interesting stumbling blocks along the way), and eventually improved observability while rolling it out to production.
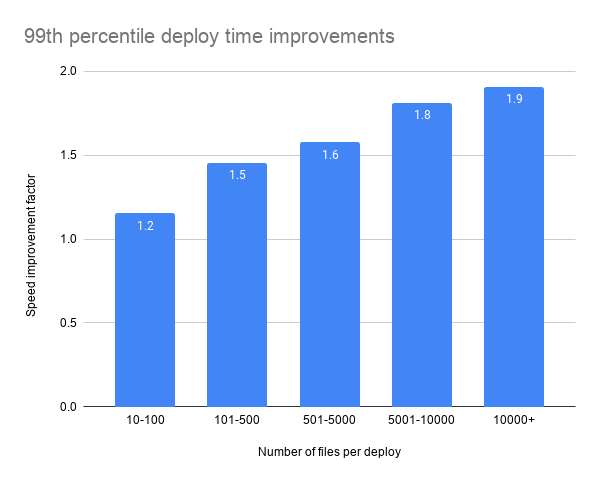
The result of this work is what we’re fondly calling “nitro deploys”, a 2x increase in the speed of our deploy mechanism. For a high level background, check out the announcement post about Netlify faster deploys. Otherwise dive in to see how we built this functionality.
Motivation
This concept of this project began as we hit an inflection point in MongoDB. Our platform was growing, and as more enterprise customers at scale were depending on us, some performance issues began to surface.
We outgrew various technical decisions we made when the company started as we took on larger and larger clients. In the interest of supporting deploys greater than 50,000 files, it became clear that we’d have to rethink our design decisions.
Previous System
In order to understand what changes we had to make, we have to dive into the implementation of what was previously one of our biggest, busiest collections: our tree collection. Here’s how this used to work:
- The client tells us the files in a deploy
- We diff that set against the bytes we already have
- We track what bytes are needed so we know when the deploy is done
- We tell the client to send us the new bytes
- They send them to us
This refactor was a major change to the way steps 2 and 3 work, the parts that diff the bytes and the parts that track them.
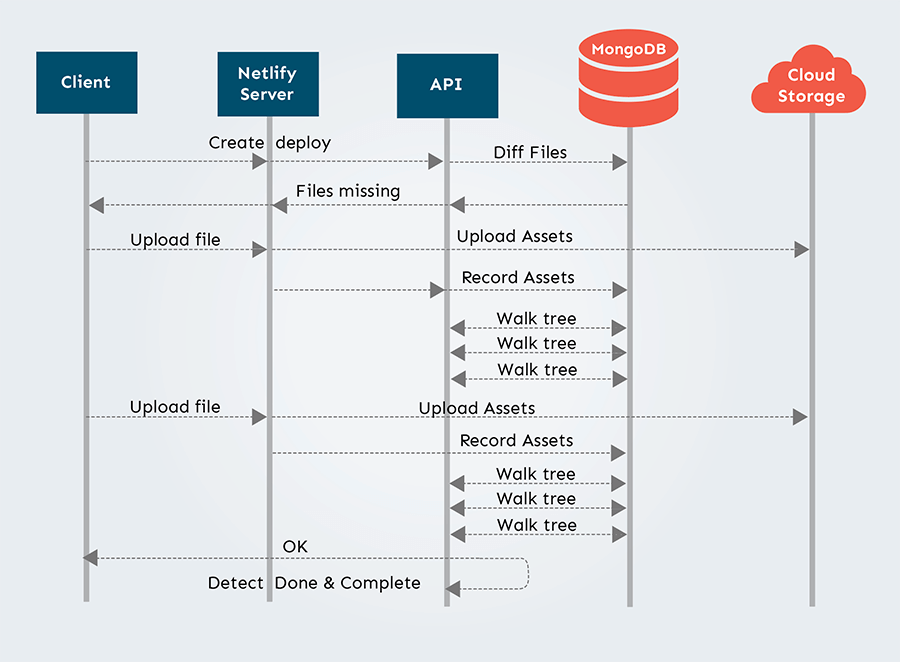
For tracking the files we use two collections in MongoDB: Trees and Blobs. Blobs track the actual location of the bytes we’ve uploaded for the customer. The Tree collection is a Merkle tree that serves two purposes: it tracks what files we already have with the current state of a deploy, and it resolves the content for a web request.
We used a tree structure here so that we could support larger deploys, and as such, there are multiple trees involved in the structure of a deploy. If we kept all the references in a single document we run into the storage limitations of MongoDB. It also helped because often large sections of a site don’t change between deploys. We could take advantage of this to have shorter tree depth to improve performance.
When a deploy is initially created, we create all the objects in the Tree collection and mark all the leaves as “needing to be uploaded”. We send that list back to the client. As they upload the file we find the leaf, update it, and then scan the whole tree to see if we’re done.
This strategy works ok for small deploys, but as you ramp up the size and the number of concurrent deploys you run into some large problems. There is a lot of read and write lock contention in MongoDB because you’re repeatedly recursively querying the same documents to determine if the deploy is complete. For large deploys, this was far more punitive because determining “if you’re done” is a lot more reads from the DB.
These performance issues highlighted that the tree collection was doing double duty, tracking the deploy state and resolving the origin requests. The underlying question became:
How do we know the state of a deploy at all times, and how do we actually consider the deploy done?
If we could separate the concerns we could maybe take some of the load from the DB while we were doing the deploy. This would help both in protecting the database, and could also lead to better diff times for the customers.
First Steps
In getting started, we asked ourselves what our unknowns were through this process. Due to the fact that people use our platform for a wide variety of projects, it’s very hard to know what files are involved in each deploy and the shape of deploys on average. Specifically, we needed to know:
- The distribution of deploy depth
- How many files were in a deploy versus new files
- How often we were hitting past optimizations in the tree search
- Is our assumption that the tree updates take the most time correct?
We started by adding more and more instrumentation to the system. Collecting that data for a bit helped enhance our visibility.
What did we find? Well, part of it was inconclusive. We saw that the deploys were all over the place in size and depth. We saw that some past optimizations were triggered sporadically.
But one thing was clear, we were repeating a significant number of operations per each file upload. Not just because it was expensive to directly correlate a file to a deploy, but also because we were trying to do many things when one file was uploaded, using just one collection – our Tree.
This confirmed we were on the right track, so the next step was to try some experiments.
The Solution
The general approach was to split out the tracking of deploy completion to a different collection and minimize the number of times we need to walk the tree collection. At a high level there were 3 big parts to the solution.
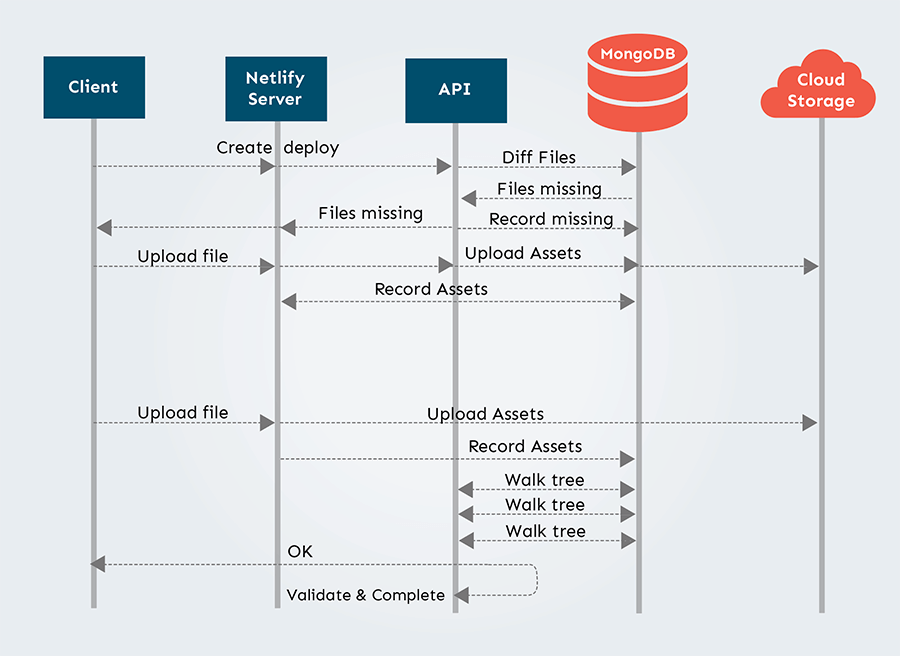
First, stop creating the tree upfront, but continue doing the diff for existence of files using the blob collection which has all the data of which files are already stored and where.
Second, since we defer creating the tree, we need a way to store the metadata for each file, so we can later reconstruct the deploy structure. This is where the new collection comes to play. At the end of the diff stage of the deploy, we’d record the files, and mark those that needed uploading. As they were uploaded to us from the client, we’d check them off in that collection as they come in.
Third, we’d defer creating and validating the final tree until the deploy was done. This means that once we think that there are no more files pending, we’d trigger the part of the system that reads the deploy tracking files, and adds that information into the tree collection, which then finalizes the deploy. After this stage, the rest of the system should continue to operate (e.g. serve web requests) as it did before.
Those are the building blocks we knew we would have to shift at a really high level. But, of course, there's more nuance in actually making this change: from coordination between different services, languages, deploy types, and deploy styles to how to roll it out on an already running system.
System architecture before
System architecture after
The Nitty Gritty
On a high level overview of the system, a file upload is three services. We have Buildbot, which is our build system, and also a client to our API. We also have Netlify Server which is a service written in Go that's in front of the API. It uploads files to our storage in the cloud. After that, it proxies requests back to the API to update all the internal logic. One thing we re-evaluated was how much work each piece was doing. Each service has access to the database – besides the client – so there's no reason why we need to call yet another service to clean up after the upload when you can do everything in one go and in one server. There's no reason to split that work because the work is all related. When we introduce an extra call, obviously, that puts pressure on our API.
From a network point of view, there's also latency involved. We gain so much more time if we could allow Netlify Server to finalize that upload and create whatever internal structure we need. As you’d expect, the previous system was longer when it had two hops than our refactor, with only one hop.
Stumbling Blocks
Depending on the size, we can identify two types of builds: synchronous and asynchronous. Builds with a limited number of files would run synchronously, while builds with more than 500 files would run asynchronously.
Besides increased performance, one of our biggest goals for this project was to simplify the complexity of running a deploy, and do everything closer to the client, with fewer hops.
We initially estimated that being able to now batch the file diff operations, reduce the work on file upload, and create the tree in the end, will allow us to run everything synchronously. This would achieve the goal of an unified logic regardless of the build size, and allow us to get rid of some of the worker infrastructure, and the extra database connections that came with it.
However, Buildbot, our client, has a strict timeout on each request. Even with the new approach, the heaviest operation is the initial file diff, that involves talking with the database, getting the Blobs that already exist, and then creating the records for the new collection. During performance tests, we noticed that up until about 30,000 files, we were well within the time limit. But when we deploy and upload more than 30,000 files, even the smallest bit of time spent adds up. This resulted in Netlify Server timing out before completing the diff.
Since touching client logic is never an easy rollout, it led us to a critical question: should we implement some sort of new queuing system for Netlify Server and migrate off the old service?
We’ve decided a new queuing system involves a much bigger effort for what would be not that much gain, and it was not the time to reinvent the wheel. We already had a solid asynchronous system in our API, which we could just refactor to make it an even better fit for the new approach.
So our initial idea of moving all the work to Netlify Server became only partially feasible. The one piece we did move was the one with the largest numbers of operations and requests – file uploads. This now exists exclusively on the Netlify Server.

Rolling it out
When rolling out a large refactor of an existing system that so many rely on, an equally important piece of work is testing and releasing it safely to production.
Initially, given our scoped units of work, we thought rolling it out would be pretty straightforward. We use feature flags- specifically a Ruby gem called Flipper. We like testing in production, and our process allows us to roll out changes from day one, behind a feature flag.
Testing changes in production allowed us to discover particular integration pain points and previously unaddressed issues in the project – like adding guardrails on finalizing the deploy in a multi-node system. Or how do we make sure Netlify Server has the latest information about a deploy, without introducing another DB query. We also had a list of edge cases and past issues we knew about, that we wanted to monitor carefully, like for example, file duplicates in large deploys.
Besides catching issues before customers do, this also allowed us to also strengthen our observability before a bigger production rollout. Or so we thought. :)
After the controlled testing was successful, we wanted to see how it will behave at scale. We scheduled a gradual roll-out, where we slowly ramp up the percentages of production deploys that would run with the new optimization, and stop if at any point we see issues. To limit potential impact, we went from 5% to 10%, to 20%.
At first, we didn't see any issues. We got to 25%. It ran in production for two hours, and everything went smoothly. Then, we started seeing reports from customers indicating there might be something wrong.
What ended up happening is that we missed a few critical edge cases. One example of this is that some projects have files that have multiple dots. To store file names safely, we need to be careful about special characters – including dots. So we encode all file paths before we add them to the corresponding tree entry. The new code had a bug in this particular part that we’ve missed.
For some of the sites, this resulted in serving incorrect files. You could still go to the URL, but you would get an invalid file. Though this wasn’t ideal, the silver lining was this: if this sort of problem would have happened in the old system, we would have an extremely hard time tracking it down. Likely our simplest course of action would have been to ask the customer to create a new deploy.
The greatest part of our new process was, despite this hiccup, we now have a record of every single deploy file, with all metadata, not just what’s uploaded and not. This allows us to rebuild the tree deploy structure at any point in time. This becomes incredibly powerful for how we tackle deploy incidents in the future.
We were then able to isolate the problem, push the fix to escape the files correctly, and reprocess those deploys so that there was no action needed from the customer. (High fives all around!)
Testing in Prod
Due to some of the edge cases we witnessed, it became increasingly clear how important both guardrails and observability were for this feature. Given the non-deterministic nature of our builds, having real production data for this optimization rather than just estimating was crucial to understanding our edge cases. This allowed us to really focus on what could be better:
- automatically mitigating if the new deploy tracking records are being created incorrectly
- identifying issues and fixing before our customers get impacted
- increasing observability to debug production unknown unknowns
We created and ran an extensive list of automated tests, and with each, we also made sure that the code handled those types of exceptions gracefully, and we have proper telemetry in place. We also added stricter guardrails between services, so that the deploy is never published in an invalid state if a problem occurs.
The result is that we could now directly determine what happened at every stage of a deploy, when it was ready, or if there was an error and where. We’ve been dreaming about this level of observability and control in our deploys for a while. From an engineering point of view, this was a huge win.
We also slightly modified our production roll-out strategy to include internal sites first: the fact that Netlify actually uses Netlify is always great for internal dogfooding!
This was followed by setting clear, strict expectations before a full release: the system needs to run in production, for 50% of all deploys, for two consecutive days, without any issues. It then needs to have a following overnight run without incidents. As excited as we were about releasing this to our customers, trading speed for safety allowed us to reduce the risks of impacting our live customer’s sites.
The results were that our testing has paid off, and this time around, we successfully enabled the feature at 100%, without any issues.
Now fully released: Nitro Deploys

When we were working on this feature, we added a little deploy log to know when nitro deploys were active ⚡️ It's since been removed.
You can now enjoy faster deploys on our platform. One of the best parts of this release was how we were able to improve our testing and observability matured, while also expanding our ability to handle massive scale and concurrency.


