It’s historically been the case that engineering operations are opaque to leaders, as well as the team members themselves. Some leaders have attempted to gather metrics around velocity, estimation and other measures, but in many ways these numbers have fallen short. They neither provided the promised predictable practice nor allowed for a healthy and productive conversation with the team members themselves.
At Netlify, we’ve found that choosing the right metrics and focusing on the team rather than the individual can motivate the entire team to consistently deliver great results.
Metrics help our team get data-driven answers to productivity roadblocks. I gave a lightning talk at the Virtual CTO Summit in July in which I mapped out our approach to metrics. Our engineering team—like so many in 2020—are distributed across the U.S. and beyond, and metrics are essential for distributed team success. To foster a healthy, sustainable engineering practice in a distributed setting, you need insights into how the team works, what gets in their way, and how to identify roadblocks so they can deliver their best work.
The Long Run
Productivity is a marathon: if your team burns out during the first few miles, the entire company is at a long-term disadvantage. And, metrics show how you can give your team greater autonomy to embrace a flexible schedule while remaining focused on results in this work-from-home reality we all face. But for metrics to work, you must remember that what you measure, you give importance to. So, metrics must be a positive driver for the culture you want to build.
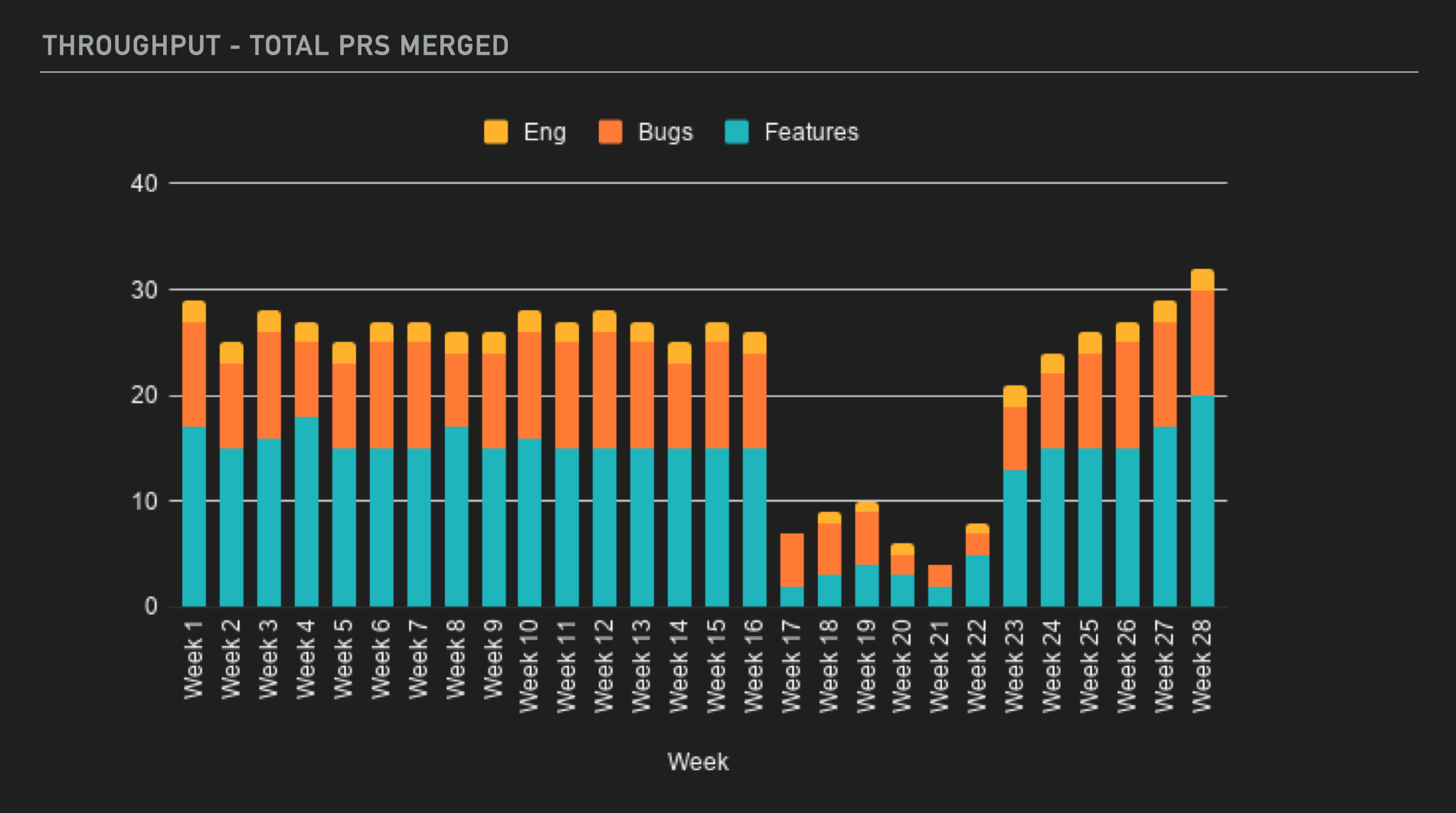
Throughput
At Netlify, throughput is expressed as the total number of pull requests merged weekly. The incentive I love about this metric is that it drives the team to deliver small, incremental changes. Focusing on small PRs means that we get quicker code reviews with less deployment risk because rollbacks are easier. I measure this to get an understanding of trends from one week to the next, and it shows me if our work is being delivered along a sustainable pace.
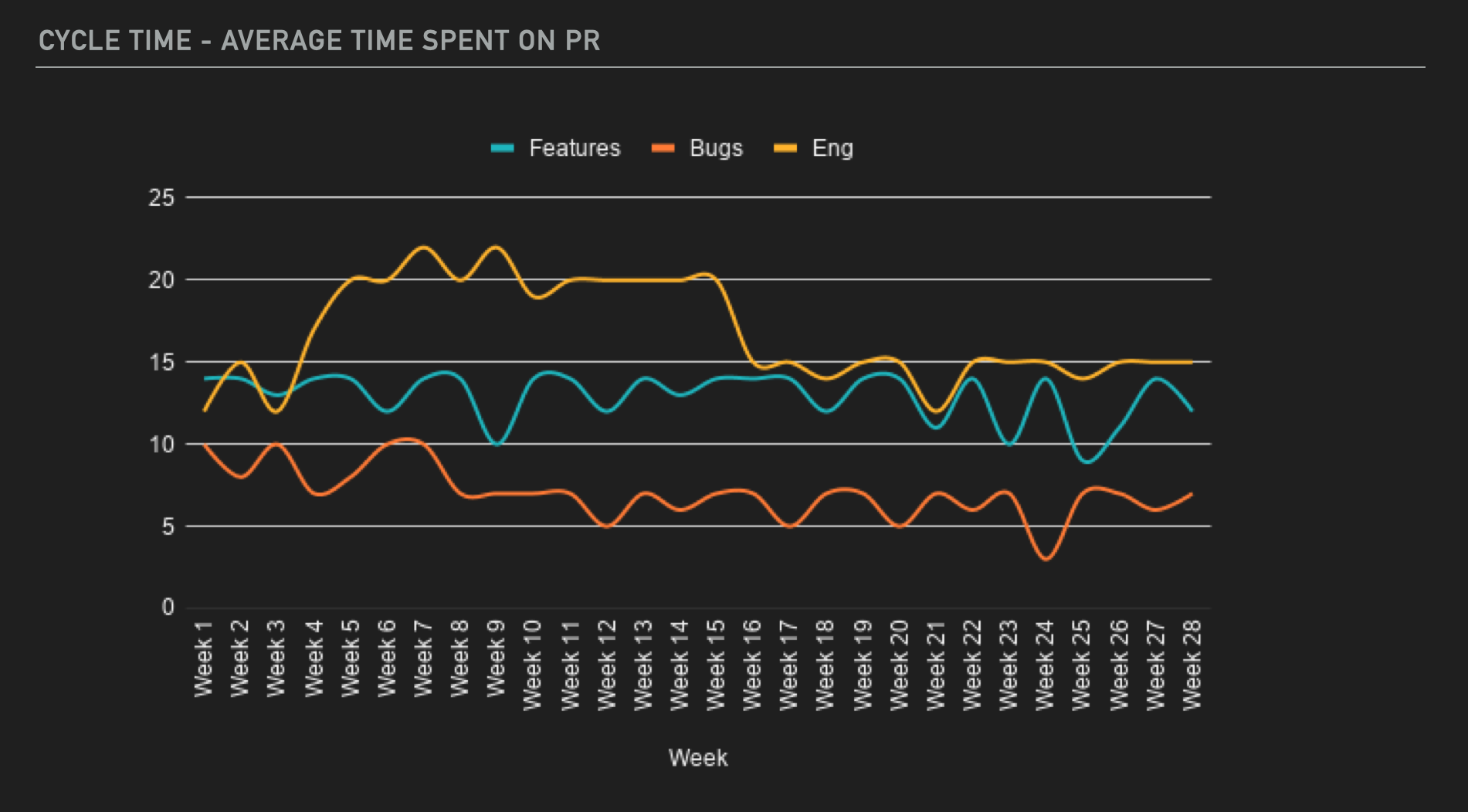
Cycle Time
I like to pair throughput with cycle time, expressed as the average number of days (or hours) it takes from the first commit to when the PR gets merged. This tells us the average time each unit of work takes to get into production. High cycle times might signal that PRs are too large, making changes more time consuming to review. Or, it could signal challenges in managing work across distributed teams and multiple time zones. Cycle time is a great metric because all engineering organizations want a quick turnaround from code to production. Focusing on cycle time helps you understand where persistent blockers are.
Quality-Based Metrics
I highly recommend pairing throughput and cycle time with quality-based metrics. Compare incidents in production by severity to throughput and you’ll get a sense for whether you’re consistently merging code that is not ready for production. A team delivering a large number of PRs to production is inefficient if the number of bugs in production is high. Quality-based metrics can help protect you from misleading indicators of success.
Taking the Pulse of Your Team
At Netlify, we use a weekly pulse survey to gain a qualitative look at team motivation, management support for team members, and our engineers’ overall support for and recommendation of the company as a place to work. You might have other “soft” metrics that matter more in your culture. The point is to think about what matters most to your organization and include that in your measurement process.
Getting Started with Metrics
The best place to begin is by taking a look at how your team is currently delivering work. You can represent a lot from just your Git data, easily capturing throughput and cycle time. Next, you should standardize across your team on the use of PR labels to make tracking consistent. Also, look at how you’re filing bugs or incidents. If you use severity labels, make sure you captured that breakdown in your metrics. For the qualitative pulse survey, a simple Google form is all it takes.
Building a Culture of Measurement
Each week, I review our metrics dashboard with the engineering management team. The session gives us a chance to discuss possible causes and understand the story that the numbers are telling us, so we can better communicate what’s happening to the team.
Too often, managers implement metrics without thinking through what those metrics are really incentivizing, and by extension, how this will impact their culture. Done the right way, metrics are a great way to empower your engineers, discuss issues openly, and develop ways to resolve them. For this to happen however, metrics should *never* be punitive. And from my experience, metrics are best when they are focused on the team and collaboration, rather than the individual. Keep it simple. Start with a few metrics. Iterate from there. Do this, and metrics can become a powerful motivator for team performance.






