At Netlify, we use a diverse set of technologies, languages and paradigms to build our product. Along with Ruby, Go, Rust and others, we write quite a bit of JavaScript. All flavors of it.
My team is responsible for several mission-critical Node.js services: the Netlify CLI, the build system and the serverless function bundler are just a few examples. Despite the sheer number of repositories we maintain, and especially considering that some of them are open-source projects with daily contributions from the community, you might be surprised to learn that our team is relatively small.
I’m convinced that one of the reasons why we’re able to cover so much surface area is the rigorous set of tools and processes that we put in place. These are built on three key principles:
-
Automation: By automating recurring tasks whenever possible, we reduce the margin for human error and free up our engineers to focus on the right things.
-
Confidence: We ship fast and often. To do this effectively, we need a culture of confidence around the code that we take to production.
-
Consistency: All our repositories share the same basic structure, conventions and tools. This reduces the amount of context switching required when changing projects, which is important for our focus and productivity.
In this article, I’ll do a deep dive on some of these processes and tools, how we use them and why they help us.
Project templates
As exciting as it is to lay the foundations for something new, starting a new Node.js project from a blank canvas is actually not a straightforward process. From scaffolding the application and the test suite, to installing all the dependencies and configuring the repository, you can find yourself spending precious time and energy before you even get to the point where you can start writing code.
We automate a lot of this with a tool called Cookiecutter. Every time we want to start a new project, we run cookiecutter gh:netlify/node-template (which points to our project template on GitHub) and fill in some details about what we’re building.
Cookiecutter takes care of creating a new repository with a fully-working Node.js application, including things like:
- a
package.jsonfile with information about the project and references to the basic dependencies; - a working test suite, integrated with code coverage reports;
- configuration files for code formatting and linting;
- contributing guidelines, a license and a code of conduct;
- GitHub-specific settings, like issue and pull request templates and GitHub Actions workflows.
By automating all of this grunt work, we can get off the ground much faster and start creating value straight away.
Using a template also provides the consistency of having the same tools and structure across every project, with the added benefit of promoting good practices from day one, regardless of the nature of the project — for example, the cost of adding a test to a proof-of-concept is much lower if all the infrastructure is already in place.
Issue and pull request templates
All the communication around any one of our projects takes place in GitHub, be it a bug report or a feature request in an issue, or a contribution via a pull request. In any of these cases, there’s a certain amount of information that is essential to get upfront, before any meaningful discussion or review can begin.
If it’s a bug report, it’s crucial to get an accurate description of any errors being shown, the steps needed to reproduce the problem, and information about the user’s environment (e.g. operating system and Node/npm versions). If it’s a code contribution, it’s important to get an understanding of the solution chosen and any caveats or limitations that it brings.
To make sure we capture this information, we use issue and pull request templates in all our repositories, so that we ask users for these essential bits of information right from the GitHub interface.
You can have different templates for different use cases: our bug report template asks users to perform specific commands to obtain information about their system that might help with troubleshooting, whereas the feature request template asks broader questions about the solution that the user is after.
Oh! More importantly, our pull request template encourages contributors to add a picture of a cute animal.
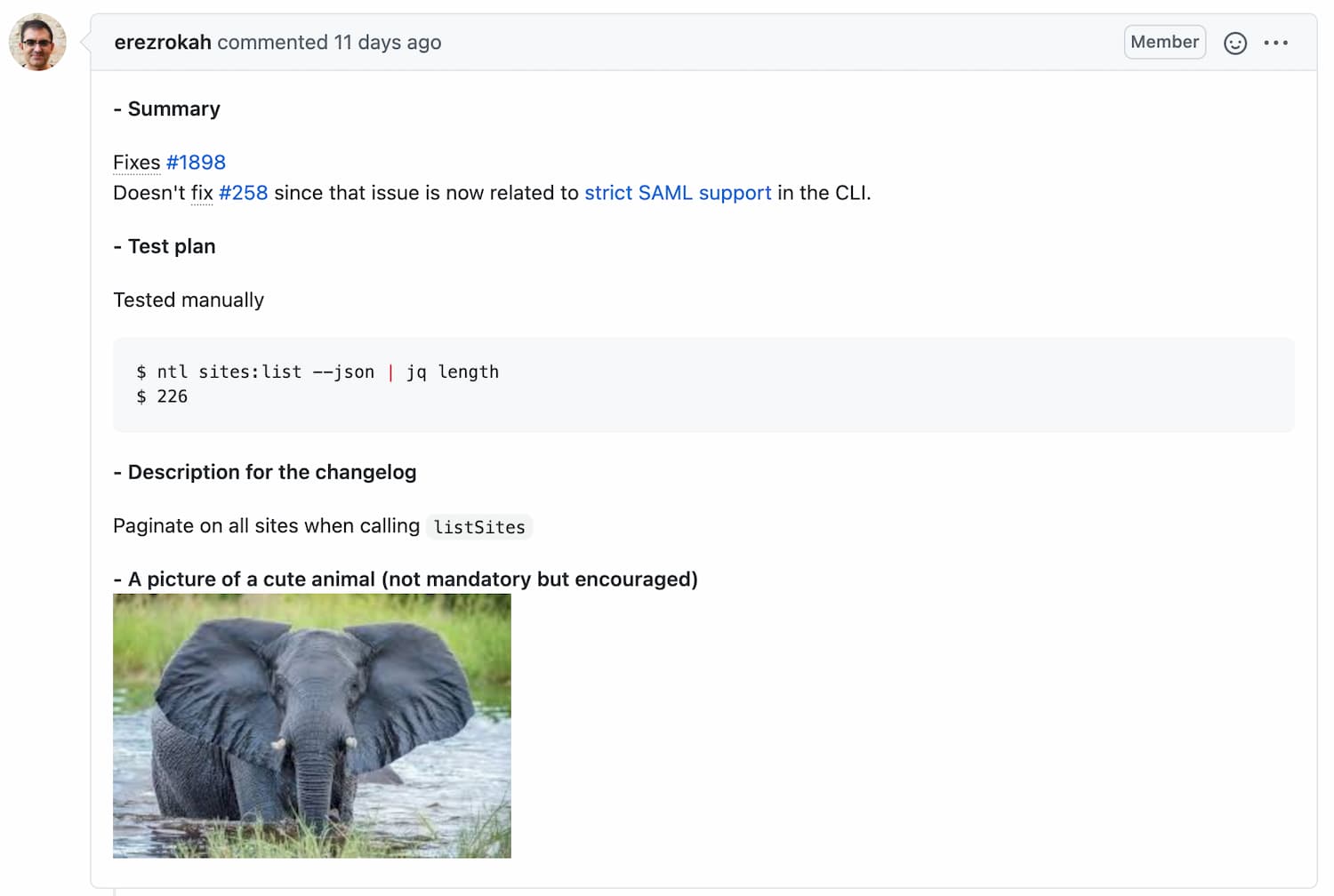
Labels
We make extensive use of GitHub labels in our issues and pull requests.
For one, this help us triage and prioritize all the open issues across our projects (which, in the case of our public repositories, can be in the hundreds). We use labels like status: need-info to flag issues that require additional information, status: blocked for issues that are blocked by another initiative, or status: wontfix to mark something that we’ve decided not to fix or implement. When a new issue is created, we do our best to address it as quickly as possible — even if we don’t have the bandwidth to work on it straight away, it’s crucial to do a triage and ask for any additional context or missing information while it’s still fresh.
At the same time, labelling our issues and pull requests provides invaluable insights into how we’re delivering our work, which is paramount for a metrics-driven engineering organization like ours. This materializes in labels that describe the type of work being carried out, like type: feature for new functionality or type: bug for a bug fix. To ensure that our work is always appropriately tagged, we have a CI workflow that automatically blocks a pull request from being merged if it doesn’t have a type: label.
Formatting and linting
In our team, engineers must have their pull requests reviewed and approved by at least one colleague before they can be merged, which is enforced in our repository settings. But code reviews are difficult and time-consuming, so we want to ensure that we focus on the right things. We want our reviews to be about the soundness of the implementation and whether the solution covers all edge cases, not about finding a missing semicolon or pointing out that a function has too many lines. It’s not that these things are not important — they absolutely are. But asking humans to enforce them is not optimal.
The solution? Automation, of course! To do this, we use a code formatter (Prettier) and a linter (ESLint).
You can think of Prettier as a typewriter that replaces the handwriting of different authors, producing a standardized and objective output that is easily understood by everyone. By using an opinionated and quite prescriptive tool, we completely stop thinking about formatting the code and just focus on the problem it needs to solve.
ESLint, on the other hand, is responsible for ensuring that the sentences that come out of the typewriter are syntactically correct. Using a linter helps us catch syntax errors earlier in the development cycle, reducing the likelihood of them making it to production.
For consistency, our Prettier and ESLint configurations are published as an npm module and imported into all our repositories. This ensures that all projects share the same rules and conventions and centralizes any modifications in one place, while making it easier to propagate updates across all projects.
Automated tests
All of our projects have a suite of automated tests. They are a fundamental piece in our engineering culture, since they give us the confidence we need to ship to production often with a lower risk of introducing regressions. A good test suite is also important when onboarding new engineers to a project, or when accepting external contributions from the open-source community.
Ava is our test runner of choice. We make use of snapshot testing in some projects (like Build), but we tend to prefer traditional assertion-based testing.
Our test suite includes an integration with Codecov to keep track of test coverage. It’s an important metric and we do keep an eye on its trajectory, but we don’t live by it. More than focusing on an arbitrary number, we measure the robustness of our test suites based on how often bugs make their way to production. Whenever that happens, we always ensure that a fix is accompanied by one or more tests to prevent that issue — or similar ones — from creeping back in.
CI/CD
We currently use GitHub Actions as our CI/CD platform. All our workflows are automatically populated by our project template, so there’s no additional configuration necessary after creating a new project.
The main job of the CI/CD pipeline is to run our test suite across different operating systems and Node versions. This is a great way to discover issues that are specific to a setup different from the one we’ve used while developing the feature. When this happens, we reach to tools like Node version managers and virtual machines to reproduce the exact conditions where the problem occurs.
Dependency management
Keeping dependencies up-to-date is another one of those repetitive, time-consuming tasks that we can offload to machines. We do this with Renovate, a GitHub App that periodically checks for newer versions of any dependencies our apps are using. When it finds an update, it offers to update them by sending a pull request with a change to your package.json and lock files, which we can decide to merge or close depending on whether we’re interested in the update.
Renovate is highly configurable. You can choose a schedule for the update events, define different settings for certain modules, or even define a group of users that will be automatically added as reviewers for any pull requests.
We have a global configuration file that is used across all projects, which we then augment on a per-project basis. For example, in our functions bundler we’re defining a list of modules that can’t be upgraded because that would introduce compatibility issues with a legacy version of Node.js that we have to support.
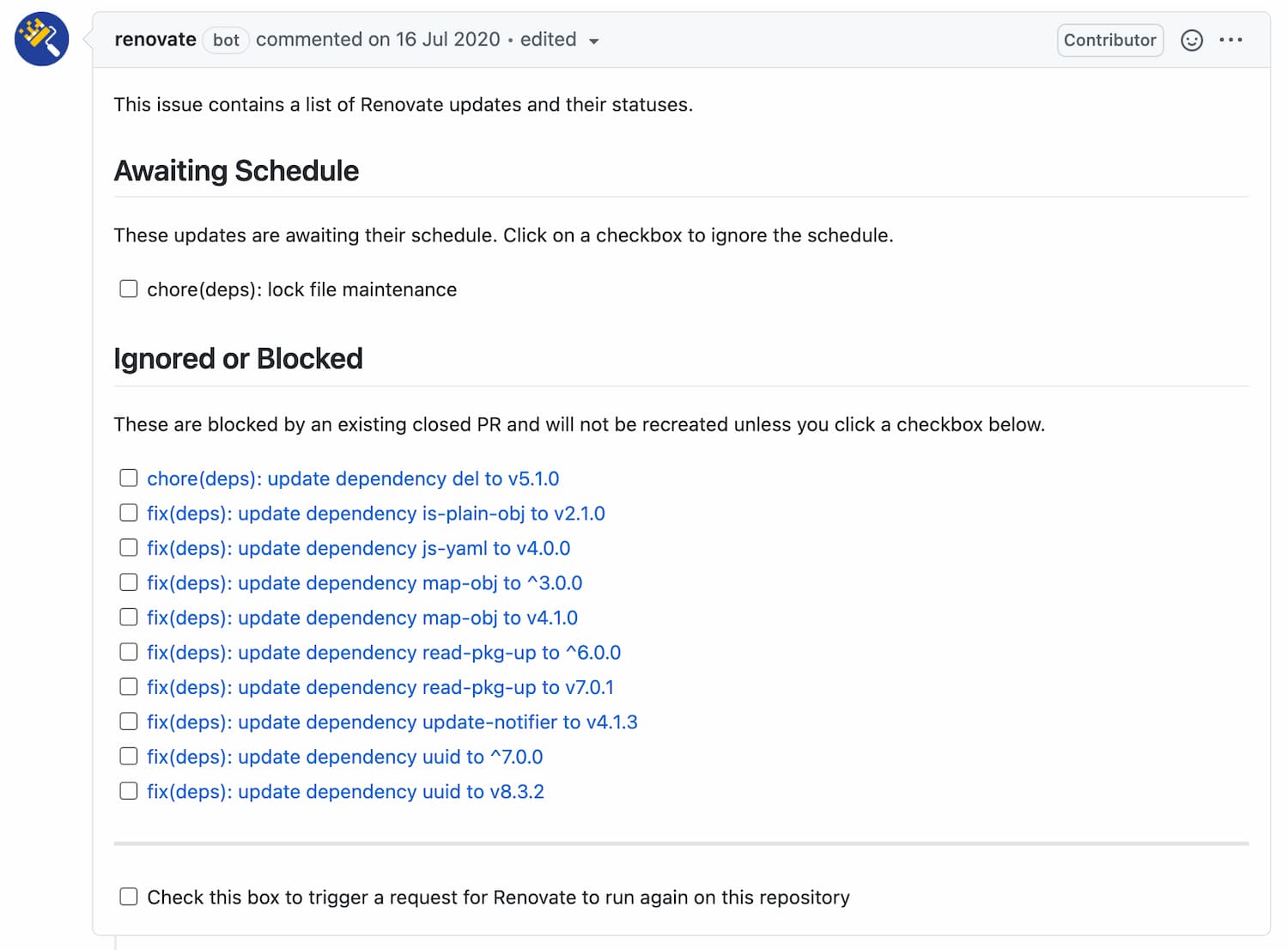
It also includes a nifty dependency dashboard right on the repository, in the form of a GitHub issue. From there, you can see which modules are scheduled for an update or trigger a re-evaluation of the dependency graph, which speeds up the creation of a pull request — I use this a lot when I’m anxiously waiting for a dependency update to cut a release!
Automated releases
Our development cycle typically culminates in releasing a new version of a module and publishing it to npm. This, too, is something that we automate.
Every commit we make follows the Conventional Commits specification, which consists of adding a prefix to the commit message according to the type of change we’re making: fix: for patch increments, feat: for minor and feat!: for major/breaking changes, all following semantic versioning.
We then use Release Please to take this data and, on every release, automatically populate the CHANGELOG file and create the appropriate tags. It also computes the upcoming version number according to the changes being released and creates a pull request to update package.json and any lock files accordingly. After this, all we have to do is run npm publish — which we’re also looking to automate, once we find a good way to handle two-factor authentication with npm.
This list is an eternal work in progress, as we’re constantly evaluating our workflows and looking for other ways to optimize our time and improve the quality of our deliverables.
It’s worth noting that these processes and automations don’t come for free — they require time themselves for an initial investigation, the setup, and ongoing maintenance. However, we generally find that time we spend on automating our workflows is an investment that pays for itself many times over, very quickly.
I hope that some of these tools and processes can help you and your team as much as they help us. Happy builds!






