Let’s say someone attended your company’s conference and wants to re-watch one of the talks. It’s a couple weeks after the talk aired, and they can’t remember the subject matter, but they’re interested in finding something the speaker mentioned towards the end. They can, however, remember that the speaker made a lot of jokes about tacos. How do they find this video in an ocean of content with only this piece of information?
Traditional methods of helping users find relevant content are all about optimizing titles, descriptions, categories, and tags. But even the best tagging strategy wouldn’t have tagged that video as taco-related.
While these standard techniques are indeed important, there’s a missing resource: How about searching the content itself? Algolia recently partnered with Netlify to do exactly this: create an in-video search for Jamstack TV, where users can find videos from the Jamstack conferences (as well as other videos) by typing in words used by the speakers or narrators in the video.
Essentially, if your videos have captions, transcripts (also generated by YouTube), and/or scripts with time signatures, there’s no reason not to provide this in-video search functionality. Searching captions with time signatures enables users to go directly to the moment in the video that is most relevant to their query.
In this article, we show you how we built this tool, and how you can implement it on your own site. Algolia TalkSearch scrapes Jamstack’s YouTube playlists and indexes the video captions using a method called “chunking”. Chunking breaks down the captions into short sentences, creating one record per sentence. This technique allows users to find the perfect moment in a video to match their search needs. We’ll then show you some essential aspects of your front end (highlighting, as-you-type instant results), using Algolia’s front-end InstantSearch library for JavaScript.
The challenges of retrieving and indexing video captions
There are two distinct challenges when working with YouTube captions.
- They are not generated immediately when you upload your video, so you need to wait an indefinite period of time before they become available. This can be days, weeks, or longer.
- The captions come in a format that requires some post-processing to index the records as sentences.
For the first challenge, we used Netlify Build to run a regular job to download the video captions. With Netlify’s serverless functions, we were able to retrieve the missing captions whenever YouTube made them available. This is a critical piece for any website that accepts external contributions, where content needs to be updated as soon as changes are made, and the whole process has to be automated. The job can be triggered via GitHub’s PR process or any other process that plugs into Netlify functions. And of course, the benefits of using Netlify’s fail-safe infrastructure that you don’t have to maintain or even know about, with Deploy Previews and error handling, are clear.
The second challenge required a combination of YouTube APIs with Algolia’s TalkSearch and indexing functionalities. Let’s take a look at this.
Parsing and Indexing YouTube Data
As an introduction to the subject, we’ll imagine someone wants to find the exact moment in a famous video, where John F. Kennedy declares “We choose to go to the moon”.
Here’s a sampling of the captions we retrieve from YouTube:
<transcript> <text start="19.10" dur="4.00">There is no strife, no prejudice, no national conflict in outer space as yet.</text> <text start="33.10" dur="2.12">But why, some say, the moon?</text> <text start="44.10" dur="5.41">Its conquest deserves the best of all mankind, and its opportunity for peaceful cooperation many never come again.</text> <text start="54.10" dur="1.01">We choose to go to the moon. </text> <text start="55.10" dur="15.16">We choose to go to the moon in this decade and do the other things, not because they are easy, but because they are hard, because that goal will serve to organize and measure the best of our energies and skills, because that challenge is one that we are willing to accept, one we are unwilling to postpone, and one which we intend to win, and the others, too'"</text></transcript>As you can see, he says “we choose to go to the moon” at the 54 and 55 minute markers.
There are 2 parts to the code:
- Getting the captions and breaking them down into sentences
- Sending the sentences to Algolia
To get the captions, you need to check to see if the captions exist in YouTube. If they do, then you parse the XML format that YouTube provides by looping through each sentence, which is a node in XML:
async getCaptions(videoId, languageCode) { // Get the content of an XML <text> node, which itself can contain // HTML-encoded tags
// ... const xml = await axios.get(captionUrl); diskLogger.write(`captions/${videoId}.xml`, xml.data);
const $ = cheerio.load(xml.data, { xmlMode: true }); const texts = $('text'); const captions = _.map(texts, (node, index) => { // We take nodes two at a time for the content const $thisNode = $(node); const thisContent = getContent($thisNode); const thisStart = _.round($thisNode.attr('start'), 2); const thisDuration = parseFloat($thisNode.attr('dur'));
const $nextNode = $(texts[index + 1]); const nextContent = getContent($nextNode); const nextDuration = parseFloat($nextNode.attr('dur') || 0);
const content = _.trim(`${thisContent} ${nextContent}`); const duration = _.round(thisDuration + nextDuration, 2);
return { content, languageCode, start: thisStart, duration, }; });
return captions; }This code essentially “chunks” the data. Chunking involves breaking up a large text into smaller pieces. Here, YouTube kindly sends us the data already chunked. The process therefore only needs to read in the chunks/sentences and create a record for each sentence.
When you see the index snippet below, you might be surprised that each sentence-record contains the same information – except, of course, the sentence, its starting time, and the YouTube URL. Here are several records (the first record is the relevant record that will match the query):
{ "title": "JFK “go to the moon” speech", "description": "JFK’s speech on the Nation's Space Effort, September 12, 1962", “youtube_url”: “https://www.youtube.com/watch?v=vy6VAKZpq4I&t=1142s”, "sentence": "There is no strife, no prejudice, no national conflict in outer space as yet.”, "Start time": “1142” }, { "title": "JFK “go to the moon” speech", "description": "JFK’s speech on the Nation's Space Effort, September 12, 1962", “youtube_url”: “https://www.youtube.com/watch?v=vy6VAKZpq4I&t=1236s”, "sentence": "We choose to go to the moon. ”, "Start time": “1236” }As you can see, these records contain the same video title and metadata. Algolia does not save data using relational database principles such as avoiding redundancy and using foreign keys. An Algolia index is not a relational database. Instead, the data is structured to be searchable in the fastest way possible, and search speed requires data redundancy. For this, we use a schemaless data structure for search. When a user searches for “choose the moon”, they should find only the relevant record. Once the engine finds it, the record must contain all of the information it will need to send back the video’s title and metadata, along with the phrase that matches the query. A modern search engine needs to be fast, fast, fast; therefore, to make search feel instantaneous for the user (in milliseconds), there’s no time to perform on-the-fly joins and other such data manipulations on the server side. The data needs to be fully ready to go as soon as it matches the query.
For more information on chunking, see our article on creating small hierarchical records for full-text searching.
Once you’ve chunked the data, you’ll need to send it to Algolia using your credentials, which you can do by looping though the sentences and sending each one using Algolia’s SaveObjects method. If you don’t have an Algolia Index, create an account and app.
Building the Front end
Now that we’ve retrieved and indexed the captions, we’re ready to search. Once again, it’s worth seeing what the interface looks like, but this time with movement to illustrate of the as-you-type instant results functionality:

There are three aspects to this front end worth mentioning here:
- The use of highlighting the matching terms
- The near instantaneous as-you-type instant results functionality
- Searchable attributes that manage the order of the results
This solution uses Algolia InstantSearch for JavaScript. With this library, you get all of the components that you see in the above GIF. Thus, you have the search bar, results in the middle, sort by feature (newest or popular). You can also enhance this experience with onscreen filtering, categories, and infinite scroll or pagination). What might not be obvious are the two absolute musts for any great front-end search experience: highlighting and as-you-type instant results.
First, here’s the front-end code (go here for the full code):
{% raw %}const searchClient = algoliasearch('{% raw %}{{ algolia.appId }}{% endraw %}', '{% raw %}{{ algolia.searchOnlyApiKey }}{% endraw %}');search.addWidgets([ instantsearch.widgets.searchBox({ container: '#searchbox', showSubmit: false, }),
instantsearch.widgets.hits({ container: '#hits', transformItems(items) { return items.map(item => { let start = item.caption.start; let obj = { ...item, url: item.caption.url }; }, templates: { item: ` <a href="{% raw %}{{ url }}{% endraw %}" class="mb-4 group jamstacktv-link"> <div class="relative jamstacktv-card"> <img src="{% raw %}{{ video.thumbnails.medium }}{% endraw %}" alt="{% raw %}{{ video.title }}{% endraw %}" class="jamstacktv-img" width="480" height="360"> <span class="jamstacktv-duration">{% raw %}{{{ displayStartInline }}{% endraw %}}{% raw %}{{ displayDuration }}{% endraw %}</span> {% raw %}{{{ scrubberHtml }}{% endraw %}} </div> <div class="jamstacktv-item {% raw %}{{ wrapperClass }}{% endraw %}"> <div class="jamstacktv-meta mb-1"> <span class="jamstacktv-category">{% raw %}{{#helpers.highlight}}{% endraw %}{ "attribute": "playlist.title" }{% raw %}{{/helpers.highlight}}{% endraw %}</span> <span class="jamstacktv-title">{% raw %}{{#helpers.highlight}}{% endraw %}{ "attribute": "video.title" }{% raw %}{{/helpers.highlight}}{% endraw %}</span> </div> <span class="jamstacktv-caption-quote">{% raw %}{{#helpers.highlight}}{% endraw %}{ "attribute": "video.sentence" }{% raw %}{{/helpers.highlight}}{% endraw %}</span> </div> </div> `, }, })]);search.start();{% endraw %}As-you-type instant results
As users type, they want to see results immediately. The results need to appear therefore as they type. They also need to be formatted so that at a glance they understand the result. A title, a thumbnail image, and short description. Additional helpful information would be speaker, duration, and name and year of conference. This comes out of the box. But there is one indication of it, where we set show Submit: false:
{% raw %} instantsearch.widgets.searchBox({ container: '#searchbox', showSubmit: false, }),{% endraw %}Highlighting matching terms
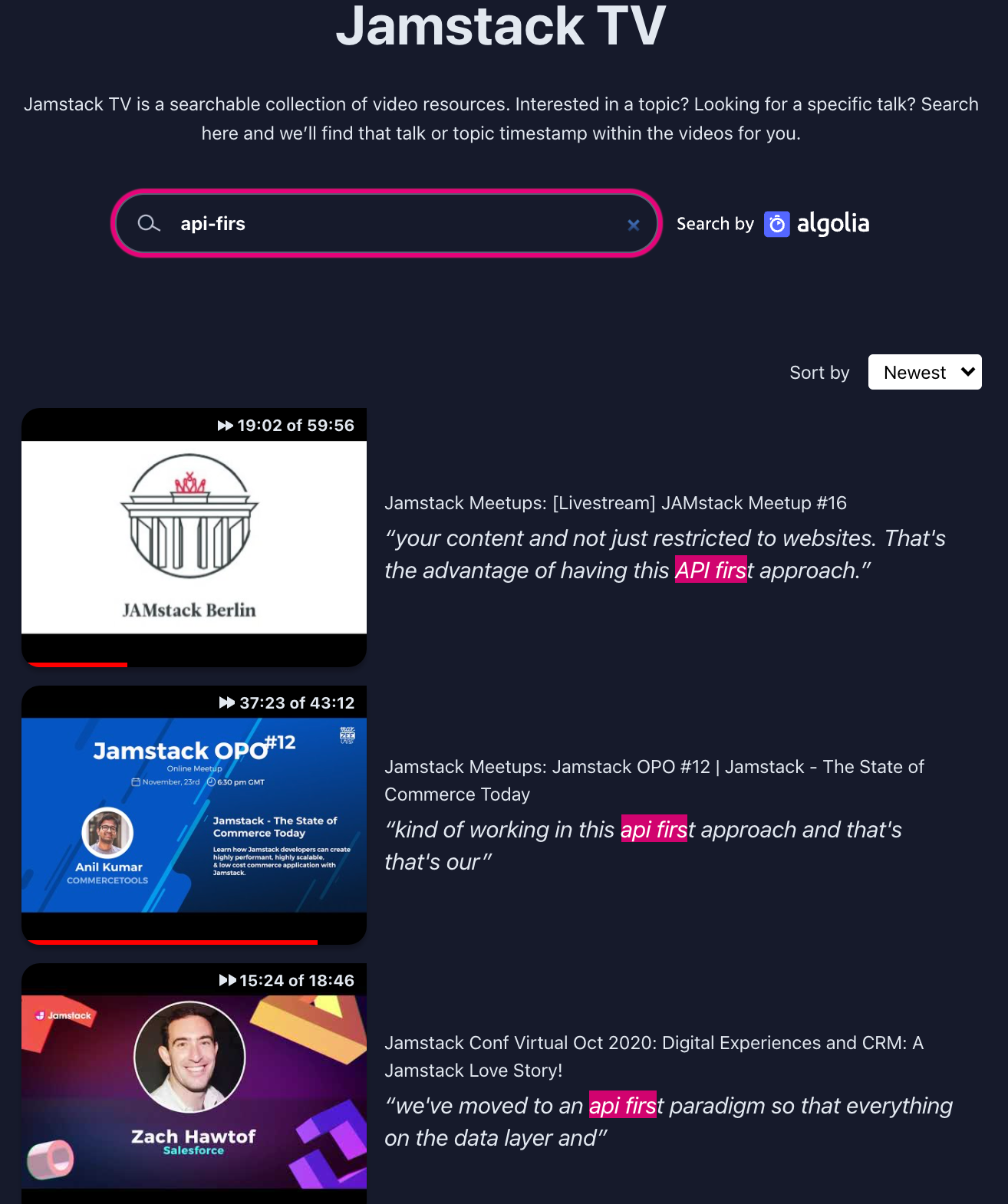
As users type, they also want to know why an item appears in the results. This is done with highlighting, as we can see here, in the pink-ish highlight:

And here’s the code for that. InstantSearch uses “templates” to format the results. You can see the full template above. Here’s the part that highlights the matching terms: {% raw %} {% raw %}{{#helpers.highlight}}{% endraw %}{ “attribute”: “playlist.title” }{% raw %}{{/helpers.highlight}}{% endraw %} {% raw %}{{#helpers.highlight}}{% endraw %}{ “attribute”: “video.title” }{% raw %}{{/helpers.highlight}}{% endraw %} {% endraw %}
Ordering the results with searchable attributes
You might have noticed that a video whose title matches the query appears before videos that match on captions:

This is a perfectly reasonable decision based on intuitiveness, which means that users would likely expect to see matches on titles, conference names, and categories, before matching on more clever items like description and captions. This is accomplished on the back end, by creating a priority list of attributes whose order in the list determines which attributes are searched first, second, and so on. In the following code, we’re telling the engine to search title and description first, then sentence, then description last. You can do this on Algolia’s dashboard, so this is not necessarily a technical task. But you can also configure your data with Algolia’s API, as follows: {% raw %} index.setSettings({ searchableAttributes: [ ‘title,alternative_title’, ‘author’, ‘unordered(text)’, ‘emails.personal’ ] }).then(() => { // done }); {% endraw %}
Conclusion
A great search experience does not have to be complicated to implement. The best site search tools enable the following standard features: instant results as you type; autocomplete functionality; great and intuitive relevance; and front-end components to build a fast and easy to use search interface.
By providing in-video search, you encourage your users to stay on your website and watch videos, rather than bouncing back to Google or YouTube. This increased engagement leads users to continue to search, browse, and discover your other content, products, and services.
You can check out the code for Jamstack TV’s GitHub repo. You can also download and clone Algolia’s TalkSearch scraper repo for any media streaming use case. To see TalkSearch in action, head over to Jamstack TV and start searching!






